"Graphical models are a marriage of between probability theory and graph theory. They provide a natural tool for dealing with two problems that occur throughout applied mathematics and engineering -- uncertainty and complexity -- and in particular they are playing an increasingly important role in the design and analysis of machine learning algorithms. Fundamental to the idea of a graphical model is the notion of modularity -- a complex system is built by combining simpler parts. Probability theory provides the glue whereby the parts are combined, ensuring that the system as a whole is consistent, and providing ways to interface models to data. The graph theoretic side of graphical models provides both an intuitively appealing interface by which humans can model highly-interacting sets of variables as well as a data structure that lends itself naturally to the design of efficient general-purpose algorithms.
Many of the classical multivariate probabilistic systems studied in fields such as statistics, systems engineering, information theory, pattern recognition and statistical mechanics are special cases of the general graphical model formalism -- examples include mixture models, factor analysis, hidden Markov models, Kalman filters and Ising models. The graphical model framework provides a way to view all of these systems as instances of a common underlying formalism. This view has many advantages -- in particular, specialized techniques that have been developed in one field can be transferred between research communities and exploited more widely. Moreover, the graphical model formalism provides a natural framework for the design of new systems." --- Michael Jordan, 1998.
We will briefly discuss the following topics (see Murphys webpage for a more extensive list).
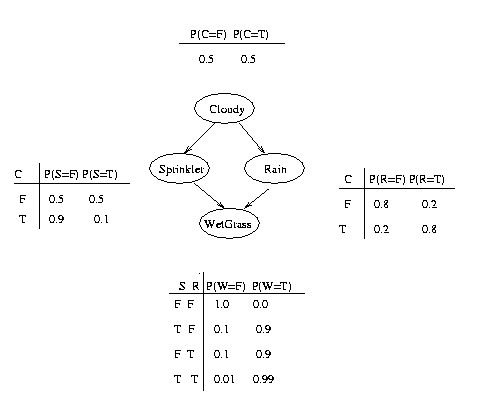
In addition to the graph structure, it is necessary to specify the parameters of the model. For an undirected model, we must specify a "potential function" for each clique in the graph. For a BN, we must specify the Conditional Probability Distribution (CPD) at each node. If the variables are discrete, this can be represented as a table (CPT), which lists the probability that the child node takes on each of its different values for each combination of values of its parents. Consider the following example, in which all nodes are binary, i.e., have two possible values, which we will denote by T (true) and F (false).
We see that the event "grass is wet" (W=true) has two possible causes: either the water sprinker is on (S=true) or it is raining (R=true). The strength of this relationship is shown in the table. For example, we see that Pr(W=true | S=true, R=false) = 0.9 (second row), and hence, Pr(W=false | S=true, R=false) = 1 - 0.9 = 0.1, since each row must sum to one. Since the C node has no parents, its CPT specifies the prior probability that it is cloudy (in this case, 0.5).
The simplest conditional independence relationship encoded in a Bayesian network can be stated as follows: a node is independent of its ancestors given its parents, where the ancestor/parent relationship is with respect to some fixed topological ordering of the nodes.
By the chain rule of probability, the joint probability of all the nodes in the graph above is
P(C, S, R, W) = P(C) * P(S|C) * P(R|C,S) * P(W|C,S,R)By using conditional independence relationships, we can rewrite this as
P(C, S, R, W) = P(C) * P(S|C) * P(R|C) * P(W|S,R)where we were allowed to simplify the third term because R is independent of S given its parent C, and the last term because W is independent of C given its parents S and R.
We can see that the conditional independence relationships allow us to represent the joint more compactly. Here the savings are minimal, but in general, if we had n binary nodes, the full joint would require O(2^n) space to represent, but the factored form would require O(n 2^k) space to represent, where k is the maximum fan-in of a node. And fewer parameters makes learning easier.
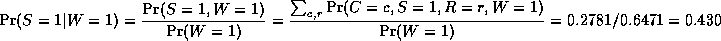
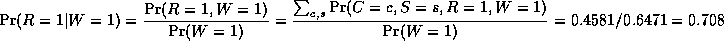
where
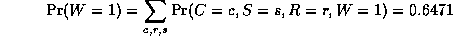
is a normalizing constant, equal to the probability (likelihood) of
the data. So we see that it is more likely that the grass is wet because
it is raining: the likelihood ratio is 0.7079/0.4298 = 1.647.
Notice that the two causes "compete" to "explain" the observed data. Hence S and R become conditionally dependent given that their common child, W, is observed, even though they are marginally independent. For example, suppose the grass is wet, but that we also know that it is raining. Then the posterior probability that the sprinkler is on goes down:
Pr(S=1|W=1,R=1) = 0.1945This is called "explaining away". In statistics, this is known as Berkson's paradox, or "selection bias". For a dramatic example of this effect, consider a college which admits students who are either brainy or sporty (or both!). Let C denote the event that someone is admitted to college, which is made true if they are either brainy (B) or sporty (S). Suppose in the general population, B and S are independent. We can model our conditional independence assumptions using a graph which is a V structure, with arrows pointing down:
B S \ / v CNow look at a population of college students (those for which C is observed to be true). It will be found that being brainy makes you less likely to be sporty and vice versa, because either property alone is sufficient to explain the evidence on C.
In the water sprinkler example, we had evidence of an effect (wet grass), and inferred the most likely cause. This is called diagnostic, or "bottom up", reasoning, since it goes from effects to causes; it is a common task in expert systems. Bayes nets can also be used for causal, or "top down", reasoning. For example, we can compute the probability that the grass will be wet given that it is cloudy. Hence Bayes nets are often called "generative" models.
The above example showed what Bayes nets can be used for. Unfortunately, the method of first computing the full joint probability distribution, and then marginalizing out the unwanted nodes, takes time which is exponential in the number of nodes. As we will see later, the key to efficient inference is to exploit the factored form of the joint, i.e., the conditional independence properties of the model. So first we study such properties in a graph-theoretic way, and then return the numerical computations in the next section.
However, we can use the factored representation of the JPD to do this more efficiently. The key idea is to "push sums in" as far as possible when summing (marginalizing) out irrelevant terms, e.g.,
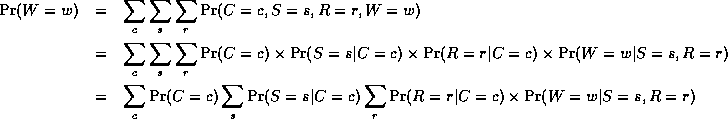
Notice that, as we perform the innermost sums, we create new terms, which need to be summed over in turn e.g.,
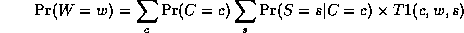
where
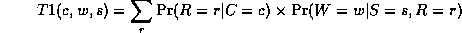
Continuing in this way,
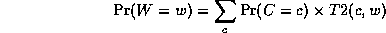
where
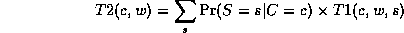
This algorithm is called Variable Elimination. The principle of distributing sums over products can be generalized greatly to apply to any commutative semiring. This forms the basis of many common algorithms, such as Viterbi decoding and the Fast Fourier Transform. For details, see